For the text mining praxis assignment, I decided to text mine three articles about Facebook. I had found these articles for an assignment in another class, “Media Literacy,” in which I had to select three clips to see how Facebook is portrayed in the news. These are the three articles I picked:
- “Sorry, not sorry: The problem with Facebook’s sorry campaign” — VentureBeat
- “Facebook Is Cannibalizing Itself” — The Motley Fool
- How Facebook Was Hacked And Why It’s A Disaster For Internet Security — Forbes
That same week, Facebook had a huge security breach that affected 50 million years, so needless to say… the coverage wasn’t exactly good. (Then again, when was the last time Facebook’s portrayal in the news been good?) And, all three articles I picked came in light of Facebook’s security breach, so it was likely referenced in some way.
My conclusions from this little “scavenger hunt” for Media Literacy were essentially how Facebook has a very negative light cast on it based on its coverage, and the abundance of negative coverage of Facebook makes it difficult for readers to know at a specific moment in time what exactly is going on with Facebook. With this text mining exercise, however, I wanted to see if there were any commonalities between the three articles I had chosen, as well as what may have been distinct about the topics each article covered.
Obviously, “Facebook” was the most common term in all of the articles…
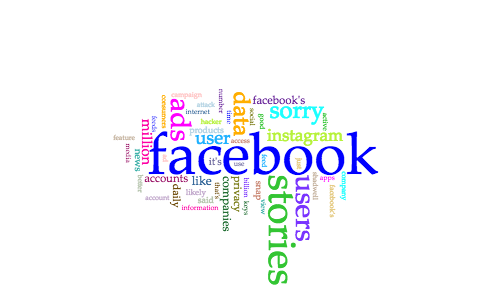
Many of the other common terms, however, were very distinct to a particular article. For instance, you can see the term “stories” is rather big in this Cirrus view — that term only appeared in the article “Facebook Is Cannibalizing Itself.” Upon further investigation (in other words, simply looking back at that article), the piece focuses on Facebook Stories and how they compare to similar features on other social media platforms, so it’d make sense the term “stories” appears specifically for that article. “Sorry,” another big term on the Cirrus view, obviously applies to the article “Sorry, not sorry.”
In terms of what all articles had in common… not much. The terms “data” and “users” appear in all articles, but there were a few different contexts in which these terms were used. (Note: “user” in singular form is also a term on the Cirrus view, but it appears in only two of the three articles.) “Data” was only referenced once in the article “How Facebook Was Hacked And Why It’s A Disaster For Internet Security,” and it seemed to only be used as an afterthought. It came in the last sentence:
“They almost certainly DO do a better job securing sensitive data than a zillion small sites would. But when they get breached, it’s a catatrasophe of ecological proportion.”
It surprised me that the term “data” would only be used once in this article since in my mind, the terms “data” and “security” come hand in hand. On another note, you see the term “privacy” in the Cirrus view as well, right? That term was distinct for the article “Sorry, not sorry,” another surprise to me.
I’ll end with some context about how the term “users” was used in each article. The obvious might be using the term when referencing the amount of users on the site, which was certainly the case.
“Next came the Cambridge Analytica news — a massive data privacy scandal that affected 87 million Facebook users.” (“Sorry, not sorry”)
“Facebook (NASDAQ:FB) now has 300 million daily active users (DAUs) on Messenger Stories and Facebook Stories.” (“Facebook Is Cannibalizing Itself”)
“Facebook dropped a bombshell on Friday when it revealed an unknown hacker had breached the site, compromising the accounts of 50 million users.” (“How Facebook Was Hacked And Why It’s A Disaster For Internet Security”)
The rest of the context of the term “users” in these articles pertained to these users taking specific actions on the platform. For example, from “Sorry, not sorry”:
“Gizmodo reported this week that Facebook allows its advertising partners to target a Facebook user by their phone number — where users gave Facebook that phone number for the implicit purpose of enabling 2FA account security.”
There wasn’t much that was similar between all three articles’ use of the term “users,” which is a reminder of how important context is when text mining. This might’ve been a text mining of rather uninteresting results, but I was excited to get my feet wet with Voyant and have realized that there’s much more work to be done than just recognizing common words that were used in all sets of texts.