Sandy’s post on our project proposal on a nonprofit news aggregation/curation site pretty much summed up everything but I wanted to add a few more thoughts, especially to clarify what I said during our presentation/Q&A.
One tentative feature we have in mind for presenting the stories (via headline and link, photo, brief excerpt) is a list of trending news topics. While the nonprofit sector is usually not in the business of covering news as it breaks, they do report on the news by providing context and giving explanations. I had mentioned during the Q&A portion of our presentation that this option (there would be multiple ways we hope to present the stories) would, for example, show the stories on mass shootings if/when one, god forbid, happens. But instead of covering the latest updates, such as the number of victims to the apprehension of the suspect and their name, the linked-to articles would instead tend to cover the shooting in the context of the bigger picture: How many mass shootings have there been so far this year? Might the latest incident prompt gun reform?
These stories would focus on the consequences and in that sense, keep the issue at the forefront longer when the rest of the media has moved on. There are overlaps, of course, between outlets that are nonprofit and those who stay abreast of breaking news, such as the Associated Press and PBS, but for our site we plan to focus primarily on the typical small nonprofit startups.
To give an example, I searched for stories related to the government shutdown, produced by members of the Institute for Nonprofit News, and here are some of the headlines:
- PolitiFact’s “What can we expect during a government shutdown?” informs readers about what happens during a shutdown, who and what it affects, and the history of U.S. government shutdowns.
- Grist Magazine’s “This is what a government shutdown over climate change would look like” puts the topic in the context of specific issues, not always covered by the major outlets.
- Other nonprofit publications such as The Connecticut Mirror and WHYY explain what a shutdown would mean for their respective regions and fill in the gaps of regional, civic and watchdog reporting oftentimes brought on by the closing of local outlets.
Going by this small sample, this potential feature would help demonstrate what sets nonprofit-generated news from much of the mainstream, often for-profit media.

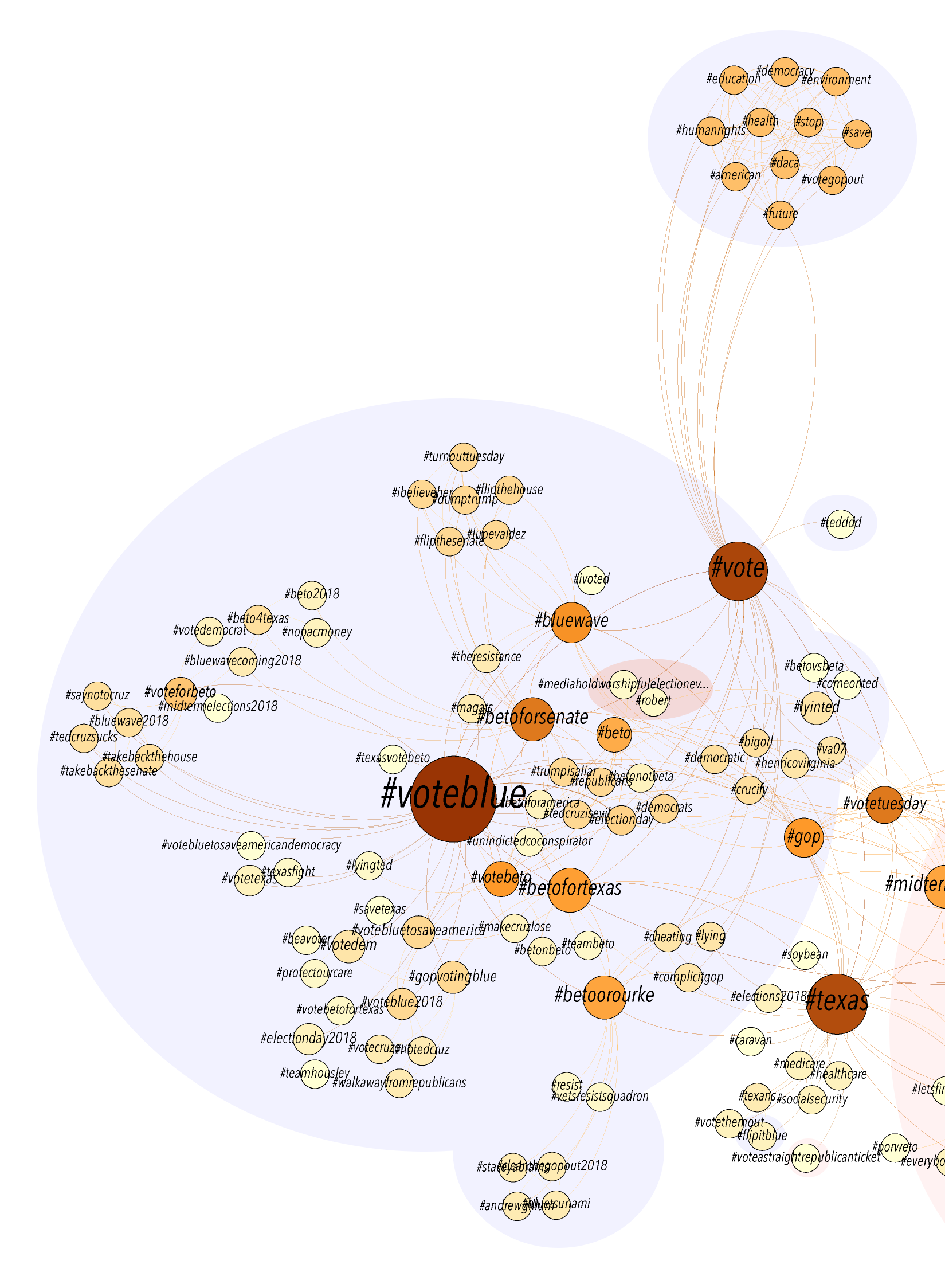
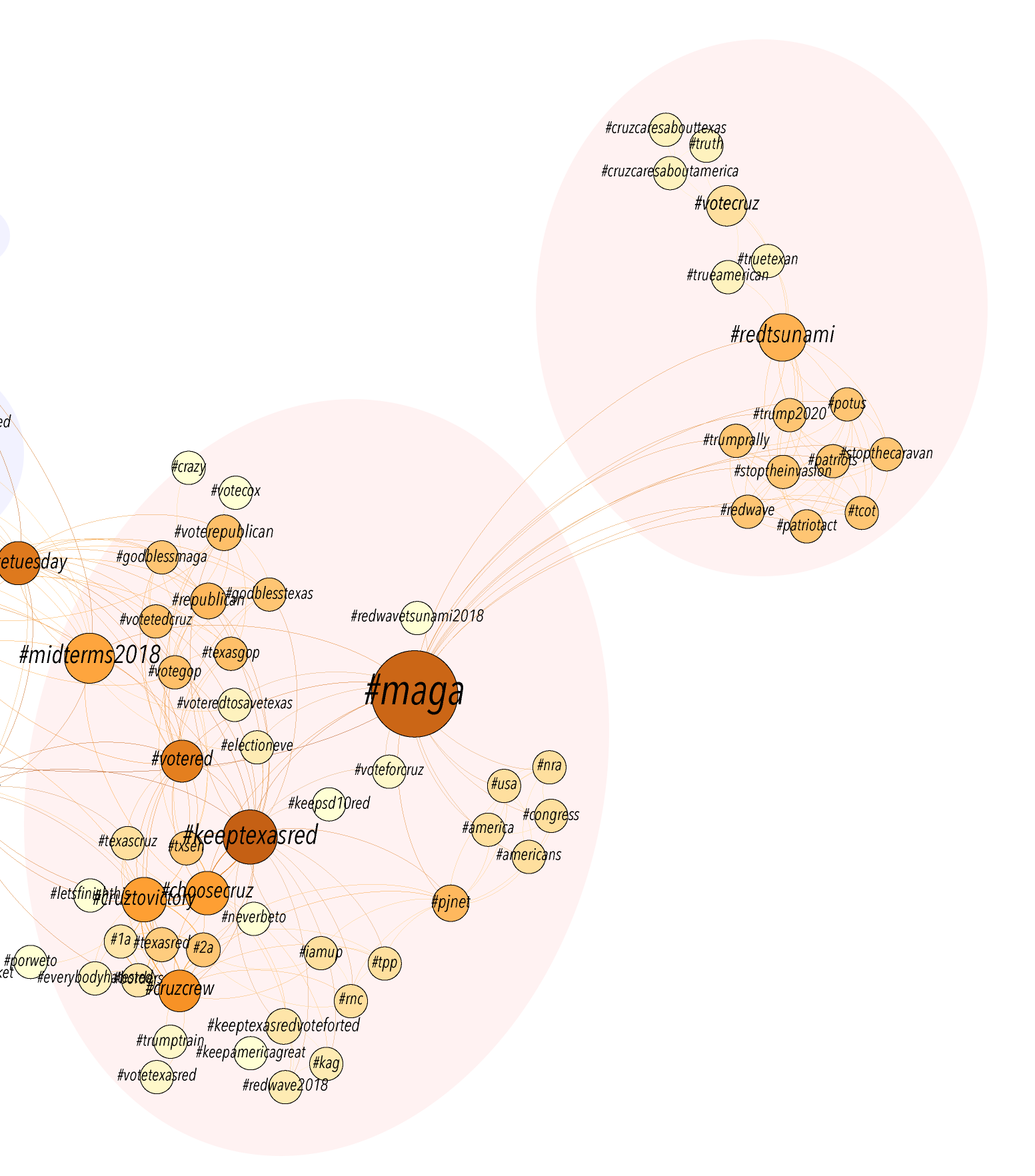




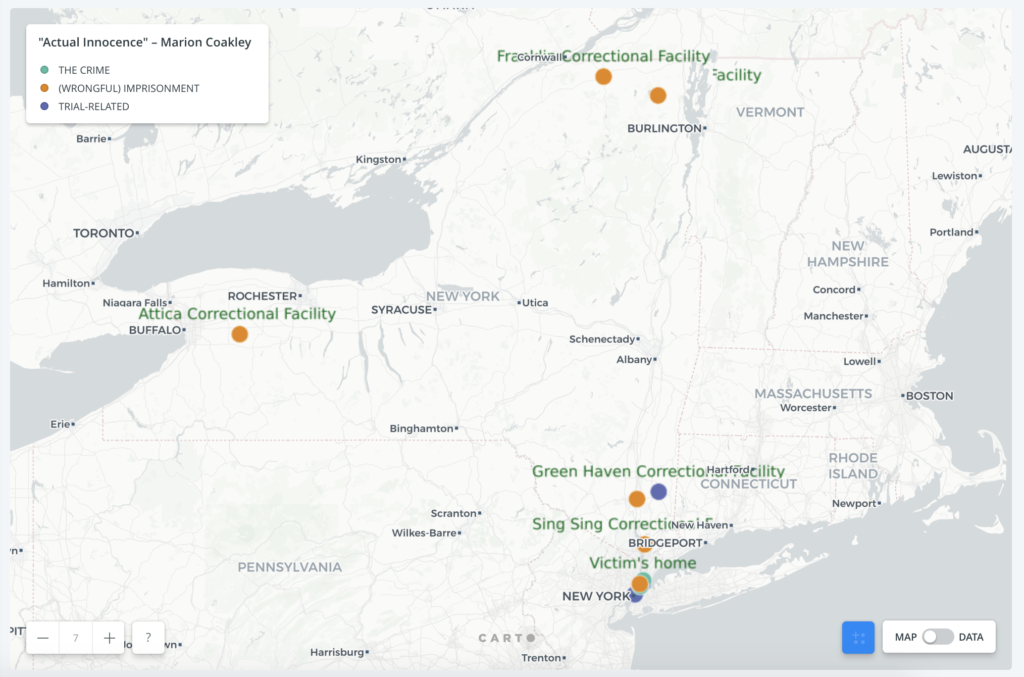
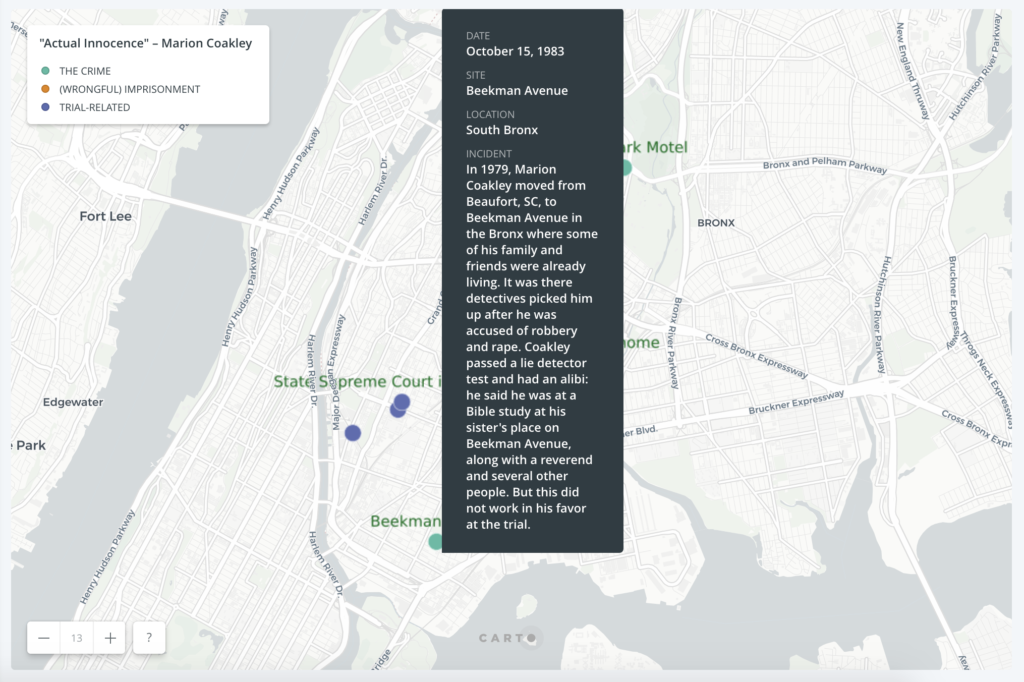 While the chronological order of the events surrounding his wrongful imprisonment remains unclear on the map, it at least gives a visual layout of the elements in the case and how far from home Coakley was as an innocent man going from prison to prison.
While the chronological order of the events surrounding his wrongful imprisonment remains unclear on the map, it at least gives a visual layout of the elements in the case and how far from home Coakley was as an innocent man going from prison to prison.