Yesterday, December 13, Megan Wacha presented a small workshop on Wikidata for librarians, and because I am totally not procrastinating from working on the final project (sorry, Rob and Hannah), I decided to share what I learned with all of you.
What is Wikidata?
Some background for those who may not be familiar: the Wikimedia Foundation is the organization that sponsors Wikipedia and several other, related projects, including the Wikimedia Commons, Wikibook, Wikiquote, and others. Wikidata, which started in 2012, is the youngest of these projects. In the last six months, Wikidata has attracted a lot of attention and funding dollars in the last six months as Ivy League universities, national libraries, and major museums have gotten involved, including the National Library of Wales, the Met, and others. Like other Wiki projects, Wikidata is the work of volunteers who believe in the mission of making information available to everybody, so it operates on an ethos of openness.
Wikidata collects structured, linked data (which I’ll explain a bit further on) about all sorts of things; the example Megan used was Sarah Schulman (a writer and CUNY faculty member), and the entries I’ve found have included:
…so as you can see, it’s really versatile. However, as a relatively new project, it’s still very incomplete!
How does Wikidata Work?
Wikidata can be edited by both humans and bots, but making the interface approachable for humans is very important. For that reason, it slightly changes the usual language of linked data to make it slightly more accessible to people who aren’t metadata or grammar experts. Where most linked data sets refer to subject, objects, and predicates, with the three together forming a triple, Wikidata uses the language of items, properties, and values.
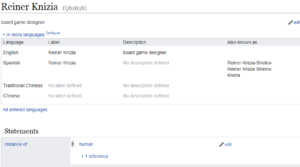
So, to stick with Reiner Knizia for a moment (and I can’t screenshot the whole thing, so this will make a lot more sense if you click through and correlate with the Wikidata item): his entry would be an item. It’s under his name, but there is also a number associated with each item as a unique identifier. His is Q61838. Knizia has several properties, that is, characteristics you could associate with him. The first is always “instance of,” which groups entries into very general categories – in this case, “human.” Other properties may vary depending on what’s in the instance property, but for humans, you get categories like “sex or gender,” “country of citizenship,” and “occupation.” The answers to the questions implied by the properties are values, so in Knizia’s case, the values of the properties listed above are “male,” “Germany,” and “game designer,” respectively. Properties can have multiple values; in this case “occupation” is “game designer,” “university professor,” and “game author.” I’m a little confused about the distinction between “game designer” and “game author,” but there are still some aspects of Wikidata that don’t quite work smoothly. There is a process for working this out, though.
In any case, the item, property and value come together to form a claim, like “Reiner Knizia is a game designer;” multiple claims can form a statement (“Reiner Knizia is a Spiel des Jahres-winning game designer from Germany.”).
One nice thing about this is that it has what catalogers call “authority control.” That is, it has the ability to distinguish among entities with the same name, and it has the ability to connect information about the same thing under different names, even across languages.
Why is Wikidata Useful?
.One of the primary original purposes of Wikidata was to gather information scattered across multiple articles. This could allow for the automatic generation of infoboxes (still not too common on English Wikipedia, largely due to a lack of references), but had some other uses as well. Wikipedia puts a lot of its articles into various categories. For instance, Knizia’s Wikipedia article puts him in “Living people,” “Board game designers.” “1957 births,” and “People from Illertissen,” which means he will automatically be included in each of these lists, and that I can go to the list of board game designers and see all the designers who have articles in Wikipedia (and I can also notice that it doesn’t include Hisashi Hayashi OR Ryan Laukat, which is nonsense and I should get on that). However, Wikipedia doesn’t provide a good way to combine these characteristics, the way you could with an AND search in any catalog, database or search engine.
For instance – I apologize for not remembering whose project this is, but one of the projects presented last week was by someone who was interested art stolen from colonized countries and currently held by Western museums, and had noted that getting this information isn’t easy! Wikipedia could be a useful tool to start with, except that you can’t look at where a work of art came from and where it’s currently located at the same time. However, Wikidata provides a possible way to do that, if the data is there. However, the data mostly isn’t there now—though it could certainly serve as a platform on which this sort of work could be conducted.
There are also several projects built on Wikidata, including:
- Wiki ShootMe! — not a good name, but this finds articles near your location that could be improved with a photograph
- Crotos — helps get at works of art in Wikimedia Commons
- Histropedia — generates timelines using SPARQL queries
- Scholia – generates information about scholarly authors, their co-authors, and where they are publishing.
Questions, Problems, and Hopes
There are a lot of things that the community is still figuring out about Wikidata.
Scope could be a problem. Where Wikipedia has strict notability guidelines, these same guidelines don’t apply to Wikidata, and the potential scope is very large – think of the list I included above. However, this data is hosted on Wikibase, the capacity of which is not infinite. One possible solution is federated wikibases. This is especially interesting in a scholarly communication context, because it creates the possibility that each institution could curate its own information about people affiliated with it, or even create a form allowing faculty to submit the bibliographic information about their work. This solves the problem of server load and the authority and vandalism problems that are always present. Of course, there is also a need for policies that will protect faculty from surveillance and trolling.
If libraries take Wikidata seriously, it could change how cataloging is done. There are still a lot of conversations happening about how to model this data, but this is an excellent time for academics to join this conversation. Currently, a lot of shared cataloging goes through OCLC, which facilitates the process but which also behaves very much like a commercial company, despite being a technical nonprofit, and which charges libraries for the work done by library colleagues.
And of course, there’s the question of how the data should be modeled and what the properties should be. Some of the data is entered automatically and edited by bots, which is very efficient but can certainly be problematic at times. The way the bots deal with gender, for instance, is not ideal. There’s also a question of who gets to be involved in this conversation, and a need for the participation of more types of libraries. Public libraries and special libraries definitely have information and models that could be useful here!
*
So, Wikidata is definitely a work in progress, but it’s a very interesting project with a lot of potential, and a way for the public to engage with data on a level that we don’t often see.
 In it you’ll find notes I took of some of Olivia’s and Javier’s suggestions interspersed with a lot of nonsense I wrote as I feverishly followed Olivia’s directions, and an odd assortment of photos I pulled at random from my files. I like how the little dog becomes the big dog; that was a lucky accident. You’ll figure out how to use ESRI easily if you just dive in and play around.
In it you’ll find notes I took of some of Olivia’s and Javier’s suggestions interspersed with a lot of nonsense I wrote as I feverishly followed Olivia’s directions, and an odd assortment of photos I pulled at random from my files. I like how the little dog becomes the big dog; that was a lucky accident. You’ll figure out how to use ESRI easily if you just dive in and play around.