Introduction
This praxis project visualizes a network analysis of the bibliographies from the September 4th required readings in our class syllabus plus the recommended “Digital Humanities” piece by Professor Gold. My selection of topic was inspired by a feeling of being swamped by PDFs and links that were accumulating in my “readings” folder with little easy-to-reference surrounding context or differentiation. Some readings seemed to be in conversation with each other, but it was hard to keep track. I wanted a visualization to help clarify points of connection between the readings. This is inherently reductionist and (unless I’m misquoting here, in which case sorry!) it makes Professor Gold “shudder”, but charting things out need not replace the things themselves. To me, it’s about creating helpful new perspectives from which to consider material and ways to help it find purchase in my brain.
Data Prep
I copy/pasted author names from the bibliographies of each reading into a spreadsheet. Data cleaning (and a potential point for the introduction of error) consisted of manually editing names as needed to make all follow the same format (last name, first initial). For items with summarized “et al” authorship, I looked up and included all author names.
I performed the network analysis in Cytoscape, aided by Miram Posner’s clear and helpful tutorial. Visualizing helped me identify and fix errors in the data, such as an extra space causing two otherwise identical names to display separately.
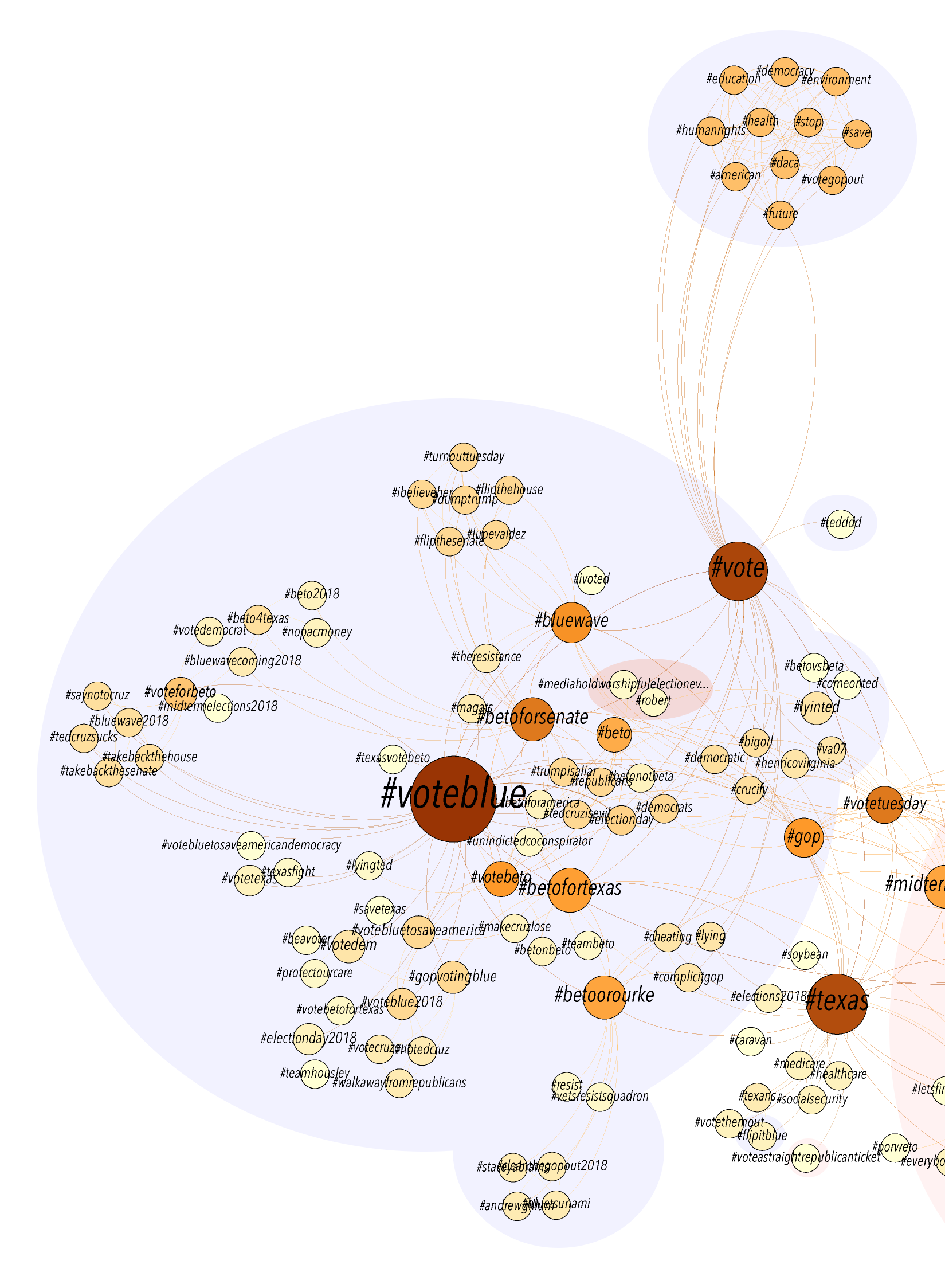
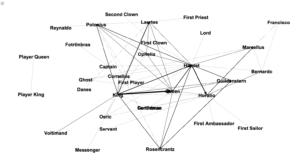
The default Circular Layout option in the “default black” style rendered an attractive graph with the nodes arranged around two perfect circles, but unfortunately the labels overlapped and many were illegible. To fix the overlapping I individually adjusted the placement of the nodes, dragging alternating nodes either toward or away from the center to create room for each label to appear and be readable in its own space. I also changed the label color from gray to white for improved contrast and added yellow directional indicators, as discussed below. I think the result is beautiful.
Network Analysis Graph
Click the placeholder image below and a high-res version will open in a new tab. You can zoom in and read all labels on the high-res file.

An interactive version of my graph is available on CyNetShare, though unfortunately that platform is stripping out my styling. The un-styled, harder-to-read, but interactive version can be seen here.
Discussion
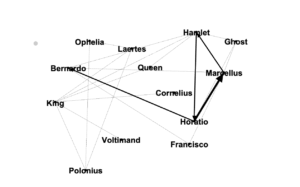
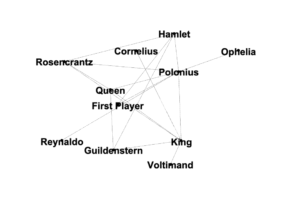
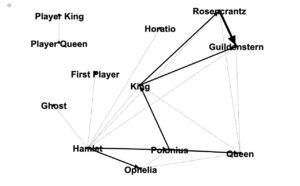
Author nodes in this graph are white circles and connecting edges are green lines. This network analysis graph is directional. The class readings are depicted with in-bound connections from the works cited terminating in yellow diamond shapes. From the clustering of yellow diamonds around certain nodes, one can identify that our readings were authored by Kirschenbaum, Fitzpatrick, Gold, Klein, Spiro, Hockey, Alvarado, Ramsey, and (off in the lower left) Burke. Some of these authors cited each other, as can be seen by the green edges between yellow-diamond-cluster nodes. Loops at a node indicate the author citing themselves. Multiple lines connecting the same two nodes indicate citations of multiple pieces by the same author.
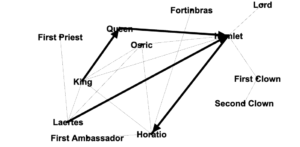
It is easy to see in this graph that all of the readings were connected in some way, with the exception of an isolated two-node constellation in the lower left of my graph. That constellation represents “The Humane Digital” by Burke, which had only one item (which was by J. Scott) in its bibliography. Neither Burke nor Scott authored nor were cited in any of the other readings, therefore they have no connections to the larger graph.
The vast majority of the nodes fall into two concentric circle forms. The outer circle contains the names of those who were cited in only one of the class readings. The inner circle contains those who were cited in more than one reading, including citations by readings-authors of other readings-authors. These inner circle authors have greater out-degree connectedness and therefore more influence in this graphed network than do the outer circle authors. The authors with the highest degree of total connections among the inner circle are Gold, Klein, Kirschenbaum, and Spiro. The inner circle is a hub of interconnected digital humanities activity.
We can see that Spiro and Hockey had comparitively extensive bibliographies, but that Spiro’s work has many more connections to the inner circle digital humanities hub. This is likely at least partly due to the fact that Hockey’s piece is from 2004, while the rest of the readings are from 2012 or 2016 (plus one which will be published next year in 2019). One possible factor, some of the other authors may not have been yet publishing related work when Hockey was writing her piece in the early 2000’s. Six of our readings were from 2012, the year of Spiro’s piece. Perhaps a much richer and more interconnected conversation about the digital humanities developed at some point between 2004 and 2012.
This network analysis and visualization is useful for me as a mnemonic aide for keeping the readings straight. It can also serve to refer a student of the digital humanities to authors they may find it useful to read more of or follow on Twitter.
A Learning about Names
I have no indication that this is or isn’t occurring in my network analysis, but in the process of working on this I realized any name changes, such as due to a change in marital status, would make an author appear as two different people. This predominantly affects women and, without a corrective in place, could make them appear less central in graphed networks.
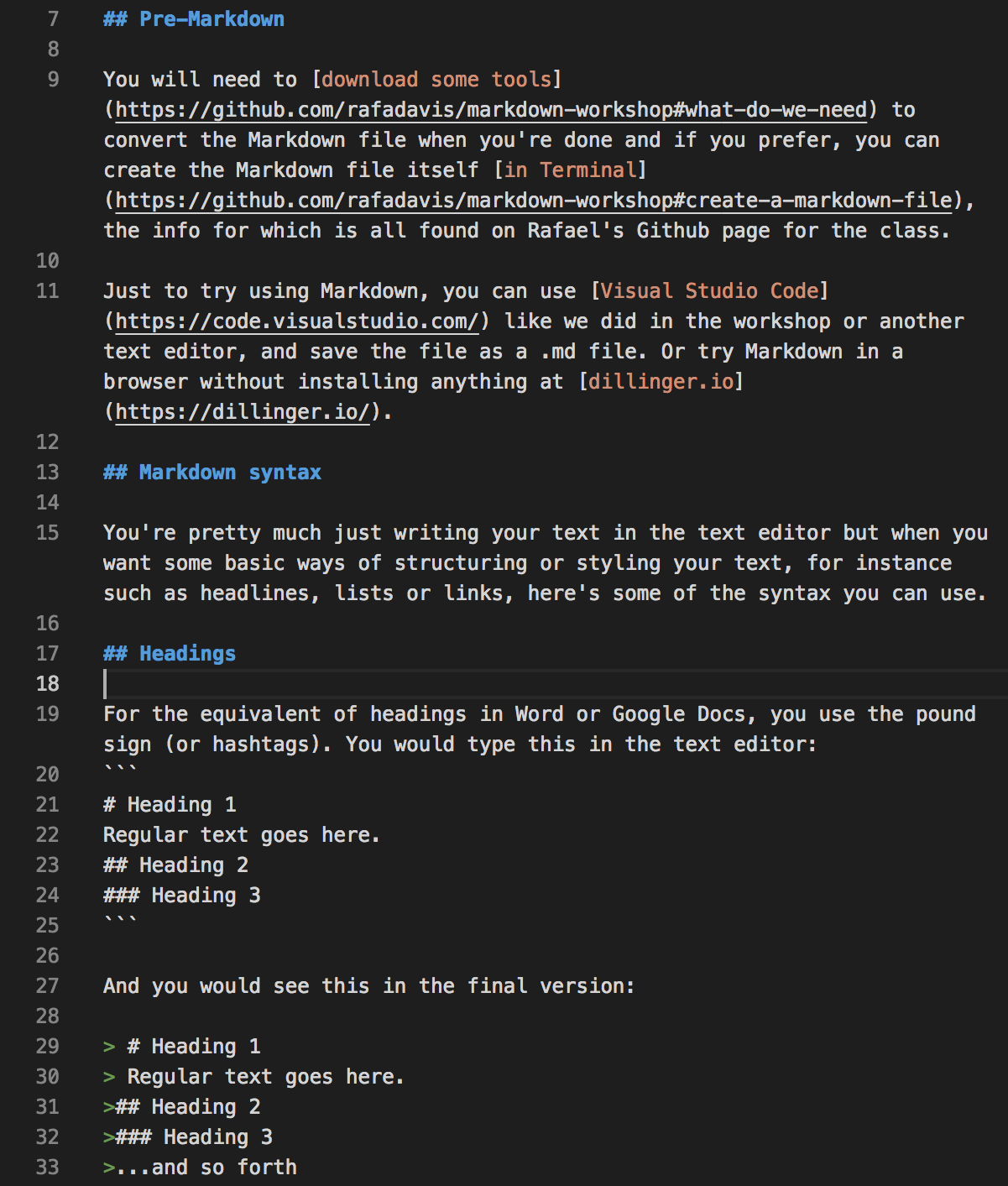
There are instances where people may have published with different sets of initials. In the bibliography to Hockey’s ‘The History of Humanities Computing,’ an article by ‘Wisbey, R.’ is listed just above a collection edited by ‘Wisbey, R. A.’ These may be the same person but it cannot be determined with certainty from the bibliography data alone. Likewise, ‘Robinson, P.’ and ‘Robinson, P. M. W.’ are separately listed authors for works about Chaucer. These are likely the same person, but without further research I cannot be 100% certain. I chose to not manually intervene and so these entries remain separate. It is useful to be aware that changing how one lists oneself in authorship may affect how algorithms understand the networks to which you belong.
Potential Problems
I would like to learn to what extent the following are problematic and what remedies may exist. My network analysis graph:
- Doesn’t distinguish between authors and editors
- I had to split apart collaborative works into individual authors
- Doesn’t include works that had no author or editor listed
—
Postscript: Loose Ties to a Current Reading
In “How Not to Teach Digital Humanities,” Ryan Cordell suggests that introductory classes should not lead with “meta-discussions about the field” or “interminable discussions of what counts or does not count [as digital humanities]”. In his experience, undergraduate and graduate students alike find this unmooring and dispiriting.
He recommends that instructors “scaffold everything [emphasis in the original]” to foster student engagement. There is no one-size-fits-all in pedagogy. Even within the same student learning may happen quicker or information may be stickier if it is presented in context or in more than one way. Providing multiple ways into the information that a course covers can lead to good student learning outcomes. It can also be useful to provide scaffolding for next steps or going beyond the basics for students who want to learn more. My network analysis graph is not perfect, but having something as a visual reference is useful to me and likely other students as well.
Cordell also endorses teaching how the digital humanities are practiced locally and clearly communicating how courses will build on each other. This can help anchor students in where their institution and education fit in with the larger discussions about what the field is and isn’t. Having gone through the handful of assigned “what is DH” pieces, I look forward to learning more about the local CUNY GC flavor in my time as a student here. This is an exciting field!
Update 11/6/18:
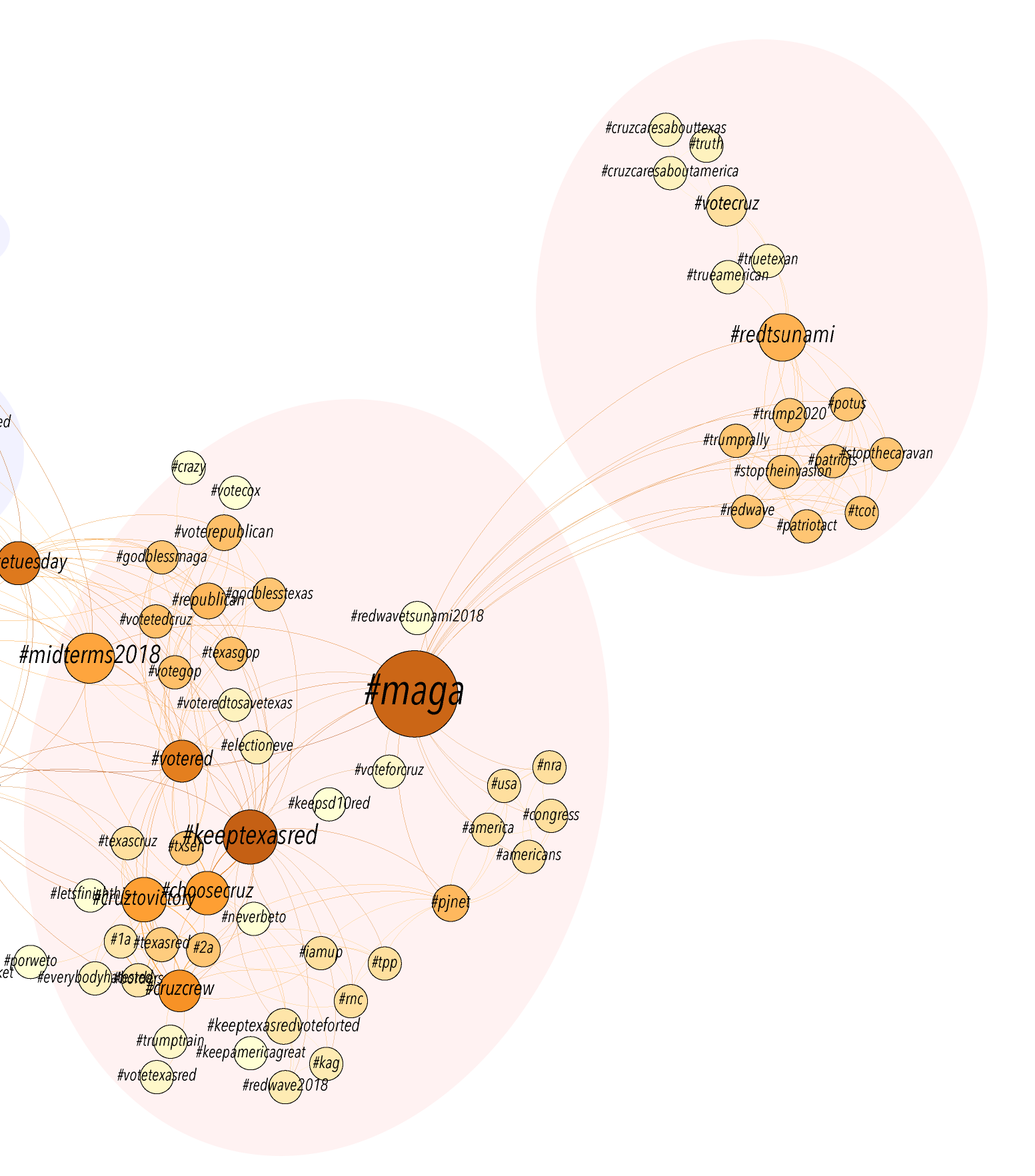
As I mentioned in the comments, it was bothering me that certain authors who appeared in the inner circle rightly belonged in the outer circle. This set of authors were ones who were cited once in the Introductions to the Debates in Digital Humanities M. K. Gold and L. Klein. Due to a challenge depicting co-authorship, M. K. Gold and L. Klein appear separately in the network article, so authors were appearing to be cited twice (once each by Gold and Klein), rather than the once time they were cited in the pieces co-authored by Gold and Klein.
I have attempted to clarify the status of those authors in the new version of my visualization below by moving them into the outer ring. It’s not a perfect solution, as each author still shows two edges instead of one, but it does make the visualization somewhat less misleading and clarifies who are the inner circle authors.