This praxis write-up is going to focus on the technical, getting data and rendering it. I do think there needs to be a purpose behind the mapping that is well spelled out both pre- and post-. This being an exercise, however, and the technical aspects taking so much time, I am going to treat mostly with the technical and logistical aspects of my efforts in this post.
Fits and Starts:
My first hazy idea was to map all the birthplaces of blues musicians and “thicken” them temporally, then add similarly mapped studios that produced their records — to see if there were interesting trends there. I found getting the data I wanted resistant to quick searches, so I started thinking about other things I might want to do.
Next up was mapping Guevara’s route in The Motorcycle Diaries. There are already a few resources out there that have done this, so I could check my work. Further, the book has a trip outline conveniently located before the work’s text. Easy. So, I opened an ArcGIS storymap and went to work, first mapping all the routes from the outline, then deciding to add text from the novel to the main points. When I started to read the text, however, I encountered much more density of spatial references than in the outline, so I added more points and began, intuitively, to transfer the entire text of the memoir into the map. What I ended up with was the idea of a new version of the book which could be read in the text window while the map frame would move to the location of each entry. This was labor intensive. For one thing, it required that I read the book again from beginning to end, not for the content so much as the setting of the content. I started to feel that it would take a very long time to do this for even a short book, and that it was not interesting enough to justify such labor without a distinct purpose for doing it. So, I did it for the first few chapters as a proof of concept and then moved on.
Link to the story map
Praxis #2 — the real effort
Kerouac’s On the Road, might be the most iconic travel narrative in 20th century American Literature. And, sure enough, many people have mapped the trip routes over the years. So, I knew there would be data out there, both for thickening my maps and comparing my findings to others’.
Methodology:
Data:
From my first attempts, it was clear that getting data is a problematic for all mapping projects. The labor involved in acquiring or generating geospatial data can be overwhelming. I can’t remember which reading this week touched on all the invisible work that goes on, mostly in libraries, to create large datasets, (“How to Lie with Maps”, I believe), but, again, it is clear that such work is to be respected and lauded. It was my intention, then, to look at ways in which data can be extracted from texts automatically — as opposed to the way I was doing it with the Guevara text — thus cutting out a huge portion of the effort required. I was partially successful.
Process:
I’ve been wanting to improve my Python skills, too, so I started there. (here is my GitHub repository)
- I set up a program in Python to load up the text of On the Road. This first part is simple. Python has built in libraries for pulling in files and then addressing them as raw text.
- Once I had the text in raw form it could be analyzed. I researched what I needed and imported the geotext package because it has a function to pull locations from a raw text.
- Pulling the locations into a geotext class allowed me to look at what geotext saw as the “cities” invoked by Kerouac in the novel.
- This list of city names pulled every instance from the text, however, so I ended up with a list that had many duplicates in it. Fortunately, Python has a built in function (set()) which returns an unordered set of all the unique items in a list. It being unordered, however, meant that I couldn’t iterate over it so I used the list() function to turn the set of unique city names back into a useable list. The figure ends up looking like this:
- list(set(location.cities))
- City names are just names (strings), so I needed to somehow grab the latitude and longitude of each referenced city and associate them with the city name. I went through an extended process of figuring out the best way to do this. Intuitively, it seemed like a master list, where city names and coordinates were joined, was the way to go. It probably is, but I found it difficult, because of my unfamiliarity with the libraries I was using, to get everything to work together, so:
- I imported the geopy package and ran through the unique list mapping each name to its geospatial coordinates (see Error below). I used the simplekml package to take the name and the coordinates to create a new “point” and then saved the resulting points into a *.kml file.
- I had to add some simple error checking in this loop to make sure I wasn’t getting null data that would stop the process in its tracks, so I added an “if location:” check since geopy was returning null if it couldn’t find coordinates for an entry in the unique list of city names.
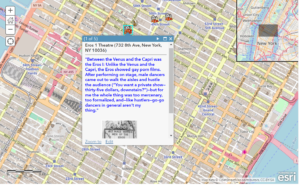
- So now I had points with only name and coordinates data. I wanted descriptions in there, too, so I imported the nltk package to handle finding the city names in the raw text file and pulling in slices of text surrounding them.
- The slices look goofy because the basic slicing process in Python uses characters rather than strings. (Note: I’m sure I could figure this out better.) So I appended ellipses (‘…’) to the beginning and end of the slices and then assigned them as the “description” of each simplekml point. (Note: I wanted to error check the nltk raw text find() function, too, which returns a “-1” for the location if it doesn’t find the entered term–so I did)
- I then pulled the kml file into a Google map to see the results.
Error:
First off, it worked. I was able to generate an intelligible map layer with a set of points that, at first glance, seemed reasonably located. And the descriptions included the city names, so that did not fail either.
Link to initial map
But there are many issues that need to be addressed (pun intended). There are multiple “bad” points rendered. I had already imagined avenues for bad data generation before viewing:
- That a person’s name is also a city or place — e.g. John Denver, Minnesota Fats
- That a city pulled by Geotext fails to find a location in geopy — fixed by error checking
- That a place that is not a city has a city’s name (see below)
- The beginning of a multi-word city name is the complete name of another place (e.g. Long Island City)
- That surrounding text (bibliographies, front matter, page notes, end notes, etc.) would have place names in them — addressed by data cleaning
- That many cities share the same name — requires disambiguation
Examining the points, I found a number of specific issues, including, but not limited to:
- “Kansas” as a city
- “Same” is apparently a city in Lithuania
- “Of” is apparently a town in Turkey
- “Mary” in Turkmenistan
- “Along” in Micronesia
- “Bar” in Sydney’s Taronga Zoo
- “Sousa” in Brazil
- “Most” in the Czech Republic
- Etc….
So, how to deal with all of this? I ran out of time to address these things in code. I would have to think more about how to do this, anyway. But here is what I did next on the map.
At https://www.dennismansker.com/ontheroad.htm, Dennis Mansker has already put up maps of the 4 “trips” recounted in On the Road. At first I just thought it would be interesting to add those as layers to my map of city name mentions. As it turns out, the new layers gave me a clear visual of potentially problematic points.
I included all 4 maps from Mansker’s site and then plotted contemporary driving directions (DD) over them. Looking at the map with all the layers active reminds me of looking at a 2D statistical plot with the median (multiple medians) drawn in. It reduced the number of points I needed to address as potential errors. Any point that fell near the DD lines, I could de-prioritize as likely “good” data. All the points surrounded by space were then easily interrogatable. This way, I discovered that the text file had not been sufficiently cleaned this way — finding a point in Japan, for instance, that corresponded with the Japanese publishing house for this edition. And I was also able to quickly see what cities Kerouac named that were not part of the “travelogue” — where he was not physically present. This could lead to some interesting inquiries.
Link to final map
More Thoughts:
I really like the idea of automating the process of data generation. Obviously, there are many ways what I did could be improved, not limited to:
- A deep dive into reducing error — i.e. the production of “bad” points
- Adding facilities to take texts as inputs from the person running the program so potentially any text could easily be analyzed and converted
- Adding facilities for looking at other geospatial data in a text
- Improving the text slicing mechanics to get more polished and applicable passages from the text into the map.
- Right now, the algorithm looks up only the first instance of a city name in the text; it would be great if it could pull in all instances (not too hard)
Getting the data and cleaning it for the purposes is a huge issue, one that dominated my efforts. I’ve left quite a bit of bad points in the map for now to illustrate the issues that I faced.
Google Maps is an easy tool with which to get going, but there are some restrictions that I encountered, namely, limited options for visualizing the points. I wanted control over the size of the icons, in particular. I would have used ArcGIS, given its power, but my kml files would not load into it. There is a huge learning curve for ArcGIS — as well as a paywall. In the future, I hope to be able to explore the mapping softwares with a bit more depth and breadth. It really helps, as in most cases, to have a goal/project to use as a vector into these complex softwares in order to begin “learning” them.




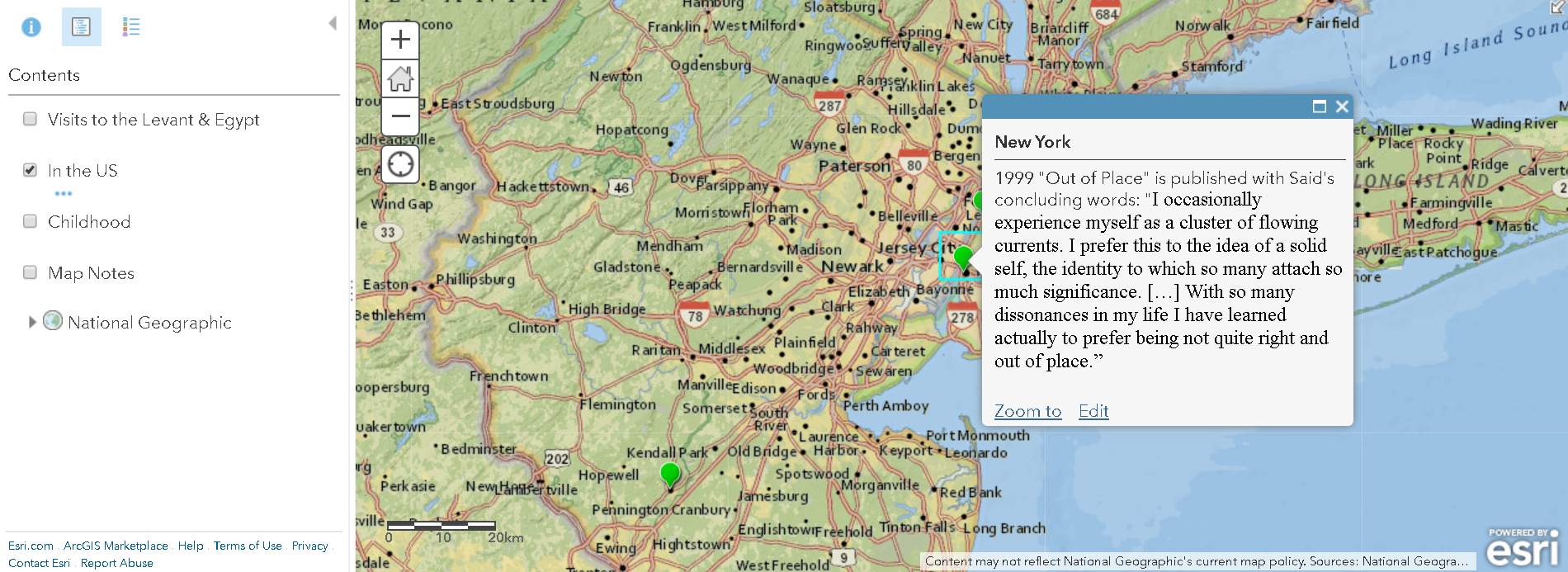
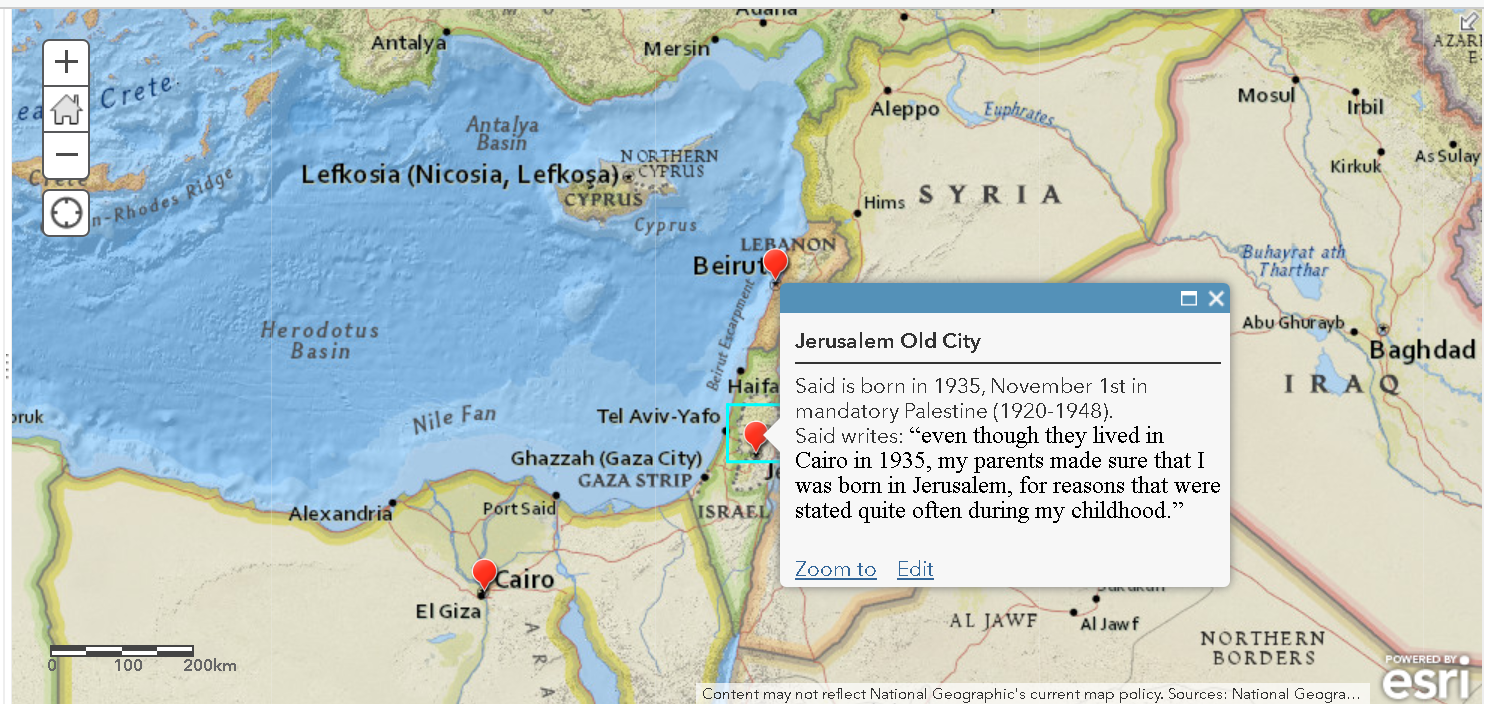

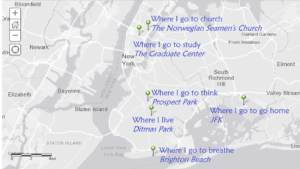
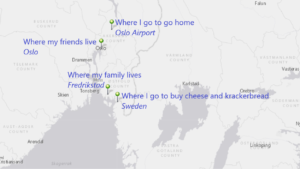
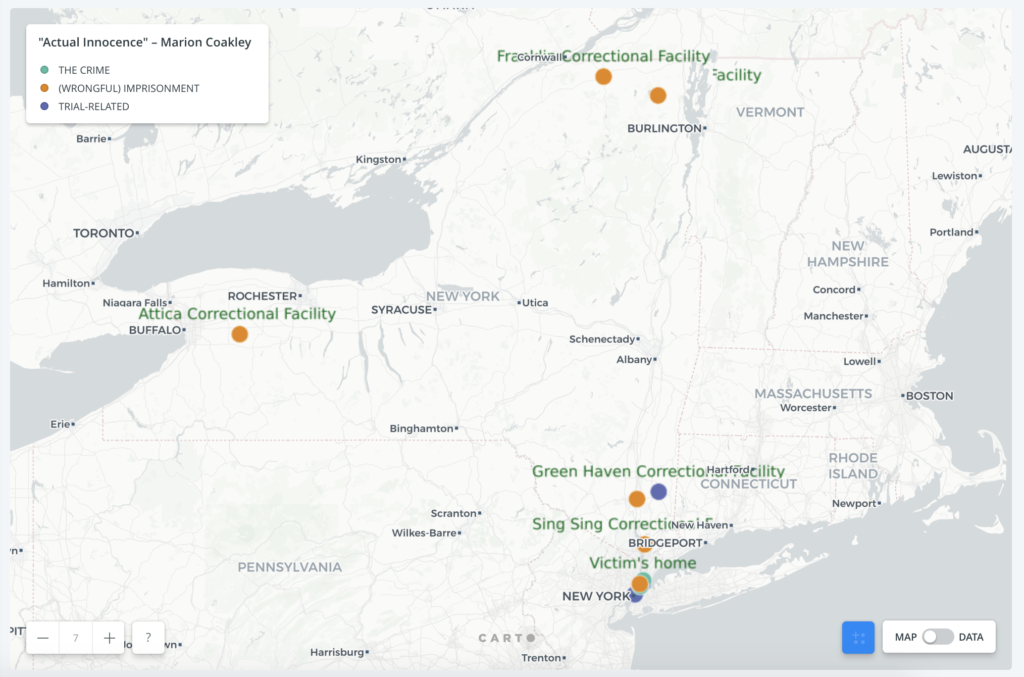
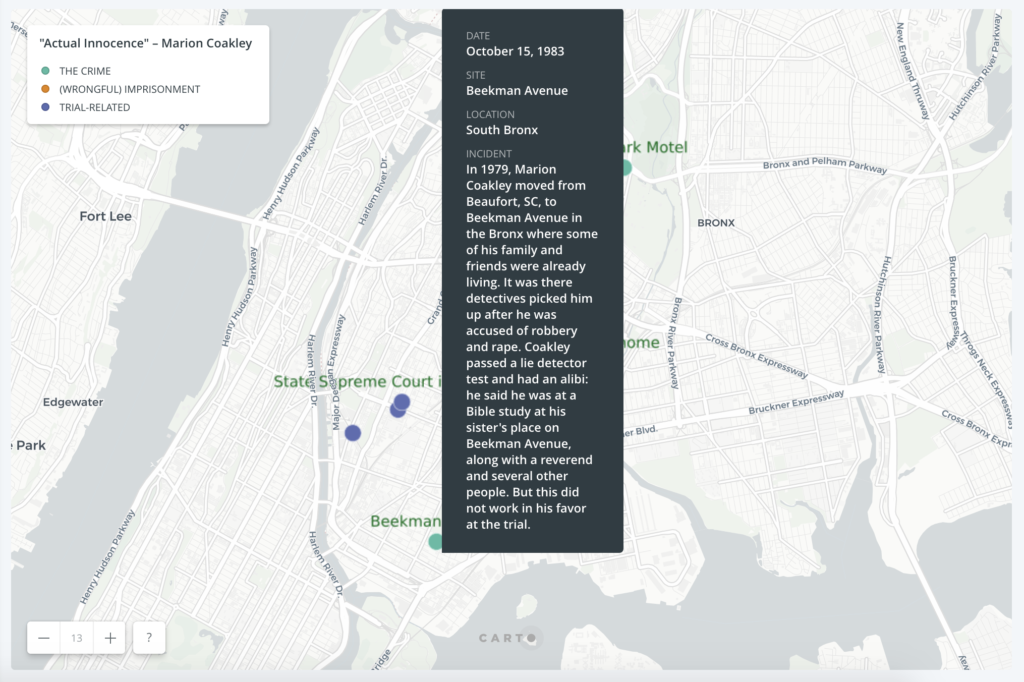 While the chronological order of the events surrounding his wrongful imprisonment remains unclear on the map, it at least gives a visual layout of the elements in the case and how far from home Coakley was as an innocent man going from prison to prison.
While the chronological order of the events surrounding his wrongful imprisonment remains unclear on the map, it at least gives a visual layout of the elements in the case and how far from home Coakley was as an innocent man going from prison to prison.